Funzioni grafiche
Questa pagina documenta le funzioni grafiche disponibili nella pagina Validazione del modello. Ogni grafico osserva il confronto fra modello e misure da un'angolazione diversa — accordo punto‑a‑punto, distribuzioni, andamento temporale, cicli, sintesi multi‑metrica e struttura spaziale — perché nessun singolo indice o grafico è sufficiente a giudicare la bontà di un modello di qualità dell'aria. Per ciascuna funzione si descrive cosa mostra, come è costruita (e da quali dati) e i motivi che ci hanno spinti a introdurla.
🕒 = la funzione scarica dati grezzi dal server (caricamento a finestre con barra di avanzamento); le altre usano i dati riassuntivi già precalcolati in i dati di validazione / i percentili, quindi sono immediate. Tutti i grafici cartesiani dispongono di una barra strumenti per esportare in CSV e in immagine (SVG/PNG), e per zoom e reset.
Accordo e bontà del modello
Grafici che confrontano direttamente modello e osservazioni per quantificare correlazione, bias (errore sistematico) e dispersione (errore casuale).
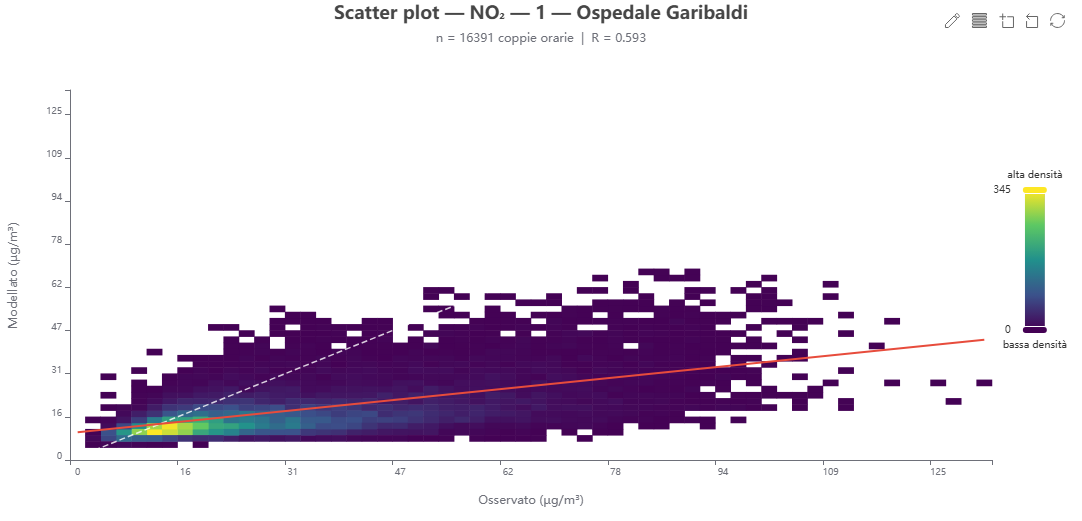
Scatter plot modello vs osservato 🕒 dati dal server
Cosa mostra. La nuvola delle coppie orarie (osservato sull'asse X, modellato sull'asse Y). Con molte migliaia di punti la nuvola è resa come heatmap di densità su griglia 60×60; sono sovrapposte la retta 1:1 (accordo perfetto) e la retta di regressione.
Come si costruisce. Le coppie sono scaricate via scatter_data (intersezione temporale fra misure di centralina e valori del modello nella cella corrispondente, filtrabile per anno/stagione/mese). Pendenza, intercetta e R provengono da i dati di validazione (record «global»).
Perché lo usiamo. È il confronto punto‑a‑punto fondamentale: mostra la dispersione, l'eventuale bias sistematico (scostamento dalla 1:1) e le non linearità della risposta del modello.
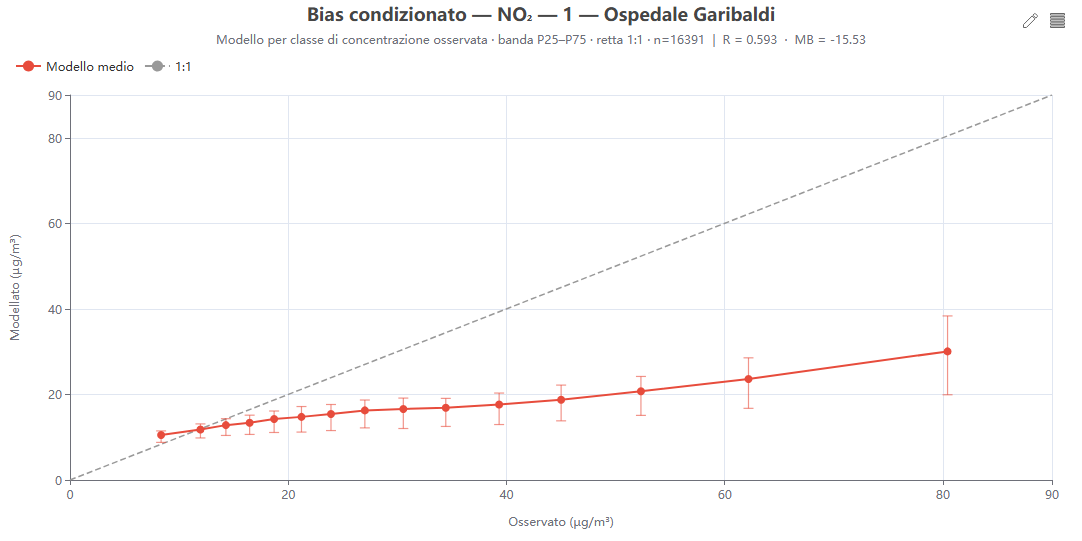
Bias condizionato alla concentrazione 🕒 dati dal server
Cosa mostra. Il valore medio del modello per ciascuna classe di concentrazione osservata, con una banda di dispersione (IQR P25–P75 oppure P10–P90), confrontato con la retta 1:1.
Come si costruisce. Le coppie obs/mod (scatter_data) sono raggruppate in classi per concentrazione osservata (a quantili, cioè numerosità uguale, oppure a larghezza uguale); per ogni classe si calcolano media osservata (ascissa), media/mediana e percentili del modello.
Perché lo usiamo. Lo scatter globale nasconde dove il modello sbaglia: questo grafico isola il bias in funzione del livello, rendendo evidente la tipica sottostima dei picchi — informazione cruciale per gli sforamenti e gli effetti sanitari.
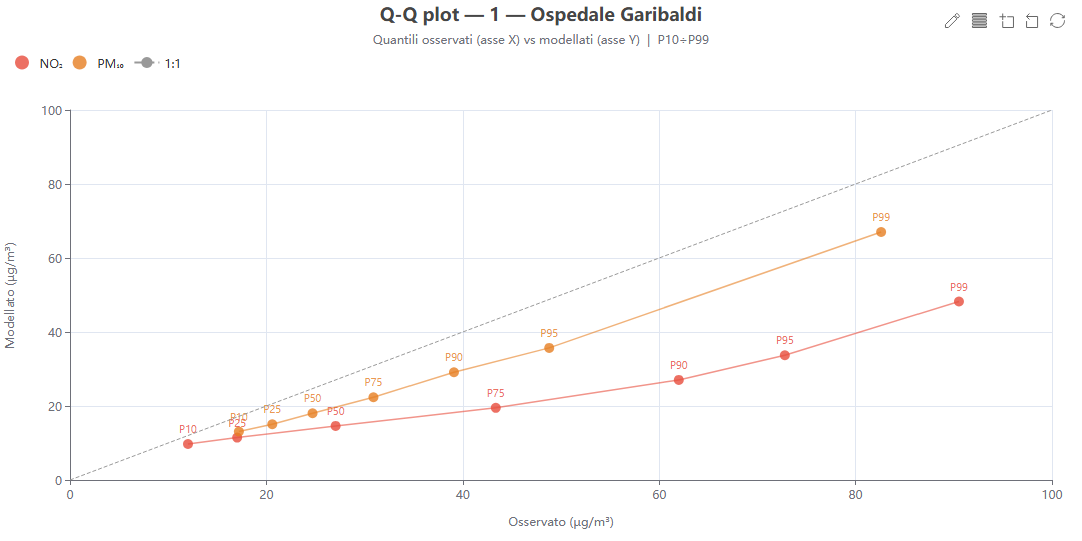
Q-Q plot
Cosa mostra. I quantili osservati contro quelli modellati (P10…P99) per ogni inquinante, con la retta 1:1.
Come si costruisce. Dai percentili precalcolati (stratificazione «global»), sorgenti measured e model.
Perché lo usiamo. Confronta le distribuzioni indipendentemente dall'accoppiamento temporale; è particolarmente sensibile ai disaccordi nelle code (valori estremi).
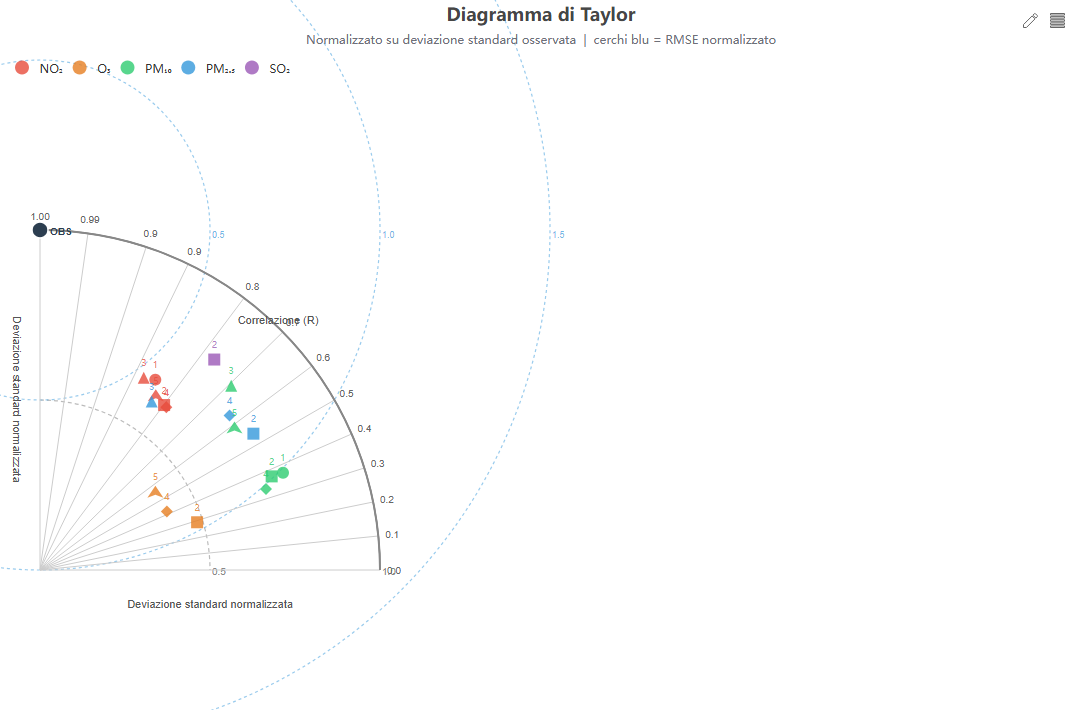
Taylor diagram
Cosa mostra. In un solo punto per centralina×inquinante: la correlazione (angolo), il rapporto fra deviazioni standard σ_mod/σ_oss (raggio) e l'RMSE normalizzato (archi centrati sul punto «osservazioni»).
Come si costruisce. Dai dati di validazione (global): r, std_obs, std_mod; l'RMSE normalizzato è √(1 + σ² − 2σR), con σ = σ_mod/σ_oss.
Perché lo usiamo. Una sola figura riassume errore di fase (R) ed errore di ampiezza (σ): è lo standard per confrontare molte serie contemporaneamente.
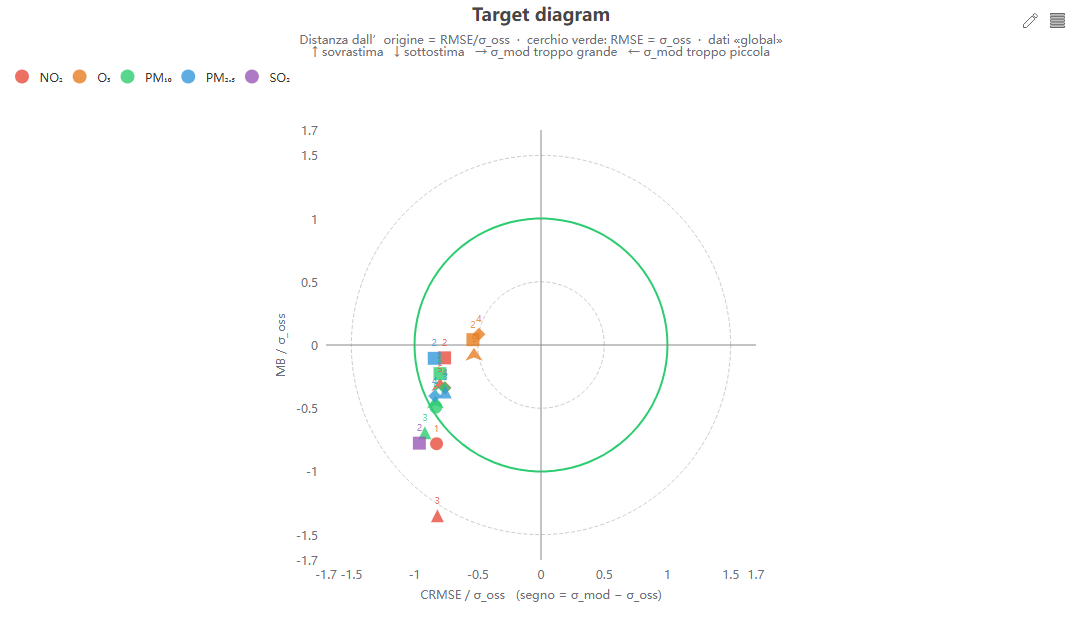
Target diagram
Cosa mostra. Il bias normalizzato (Y) contro l'errore centrato normalizzato con segno (X); la distanza dall'origine è RMSE/σ_oss e il cerchio verde (raggio 1) indica un errore pari alla variabilità osservata.
Come si costruisce. Variante di Jolliff: da mb, crmse, std_obs, std_mod — X = sign(σ_mod − σ_oss)·CRMSE/σ_oss, Y = MB/σ_oss (vale RMSE² = MB² + CRMSE²). Normalizzazione su σ_oss perché non disponiamo dell'incertezza di misura richiesta dall'MQI FAIRMODE.
Perché lo usiamo. Classifica a colpo d'occhio sia la qualità (vicinanza all'origine) sia il tipo di errore: il quadrante indica sovra/sottostima e variabilità eccessiva/insufficiente.
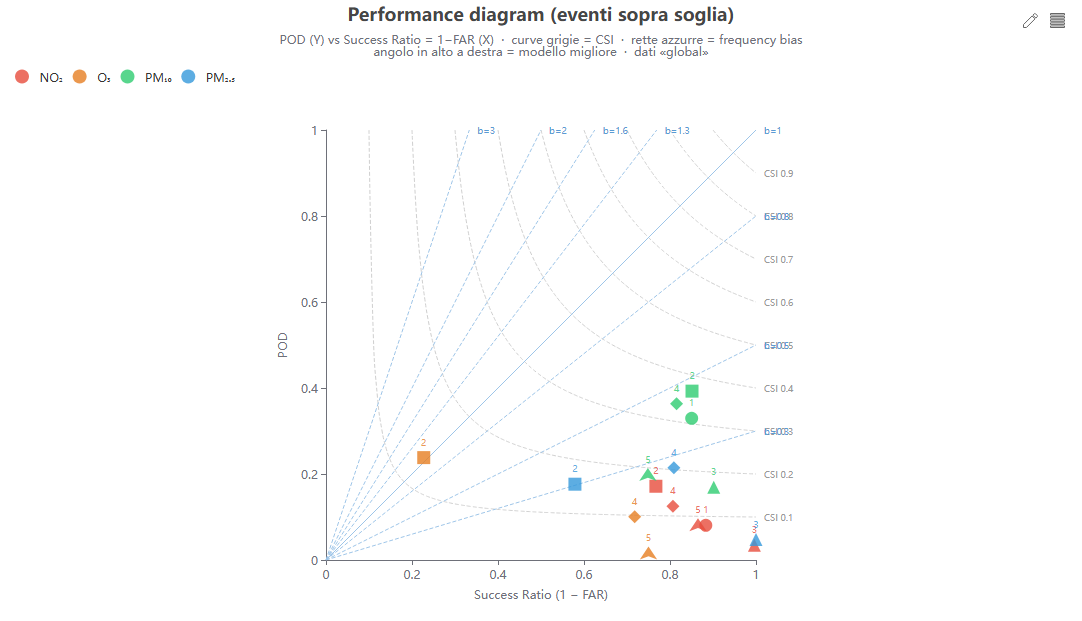
Performance diagram
Cosa mostra. Per gli eventi sopra soglia: POD (probabilità di rilevamento) contro Success Ratio (1−FAR), con curve di CSI e rette di frequency bias sullo sfondo. L'angolo in alto a destra è il modello perfetto.
Come si costruisce. Da pod/far nei dati di validazione (la soglia evento è predefinita). Le curve di CSI e le rette di bias sono tracciate analiticamente.
Perché lo usiamo. Le metriche continue non catturano la capacità di prevedere gli sforamenti: qui si bilanciano allarmi mancati e falsi allarmi, aspetto centrale per la salute pubblica.
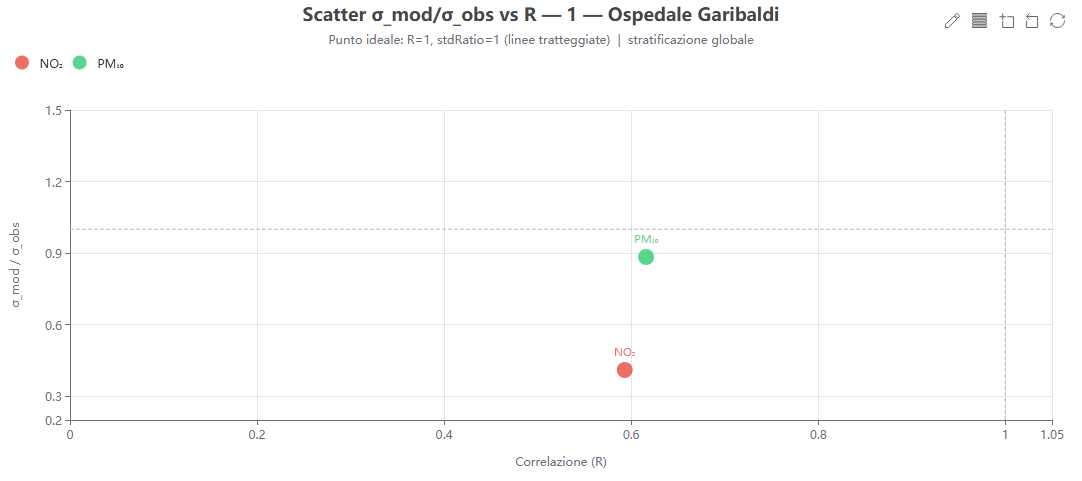
Scatter σ-ratio vs R
Cosa mostra. Per una centralina, ogni inquinante come punto di coordinate (R, σ_mod/σ_oss), con le linee ideali R = 1 e stdRatio = 1.
Come si costruisce. Dai dati di validazione (global).
Perché lo usiamo. Separa visivamente l'errore di fase (R basso) dall'errore di ampiezza (stdRatio diverso da 1), orientando la diagnosi delle cause.
Taylor diagram 3D — stagione (asse Z)
Cosa mostra. Il Taylor diagram esteso a una terza dimensione: ogni livello sull'asse Z è una stagione, così da vedere come l'accordo cambia nell'arco dell'anno.
Come si costruisce. Stessi ingredienti del Taylor (r, σ_mod, σ_oss) ma estratti per stratificazione «season»; archi di riferimento replicati per ogni livello (resa con ECharts GL).
Perché lo usiamo. Individua le stagioni in cui il modello peggiora (es. inversioni invernali, fotochimica estiva).

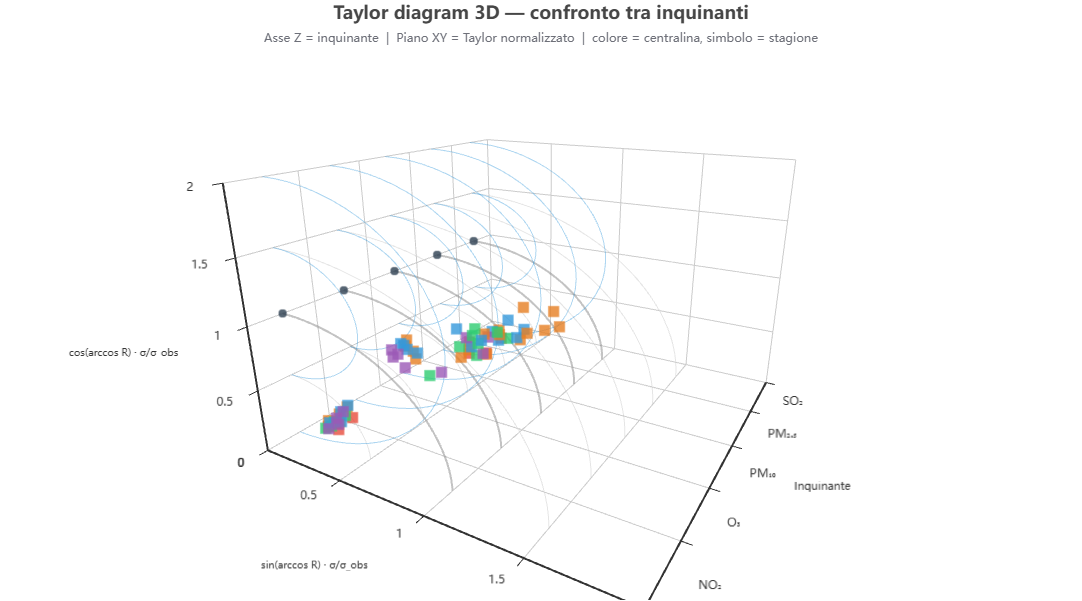
Taylor diagram 3D — inquinante (asse Z)
Cosa mostra. Come sopra, ma l'asse Z scorre gli inquinanti: confronta in un unico spazio la bontà del modello per le diverse specie.
Come si costruisce. Dai dati di validazione (global), un piano Taylor per inquinante.
Perché lo usiamo. Mette in fila i punti di forza/debolezza del modello per ciascun inquinante.
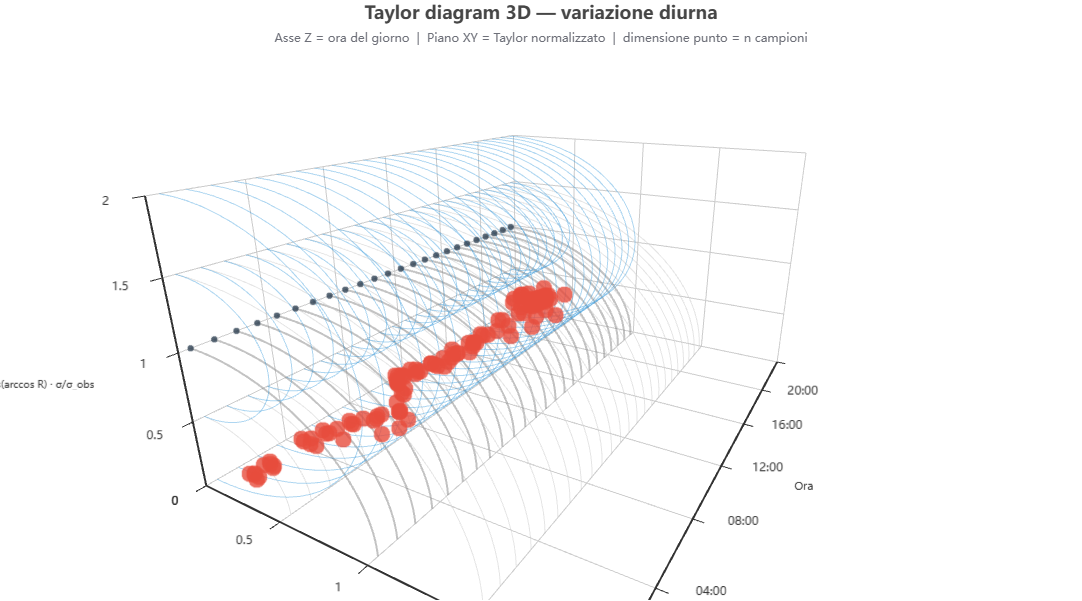
Taylor diagram 3D — ora del giorno (asse Z)
Cosa mostra. Il Taylor diagram con l'ora del giorno sull'asse Z: come varia l'accordo nelle 24 ore.
Come si costruisce. Dai dati di validazione (stratificazione «hour»).
Perché lo usiamo. Rivela le fasce orarie critiche (ore di punta del traffico, picco fotochimico pomeridiano).
Andamento temporale
Grafici che seguono l'evoluzione nel tempo di misure e modello, dai singoli episodi ai cicli ricorrenti.
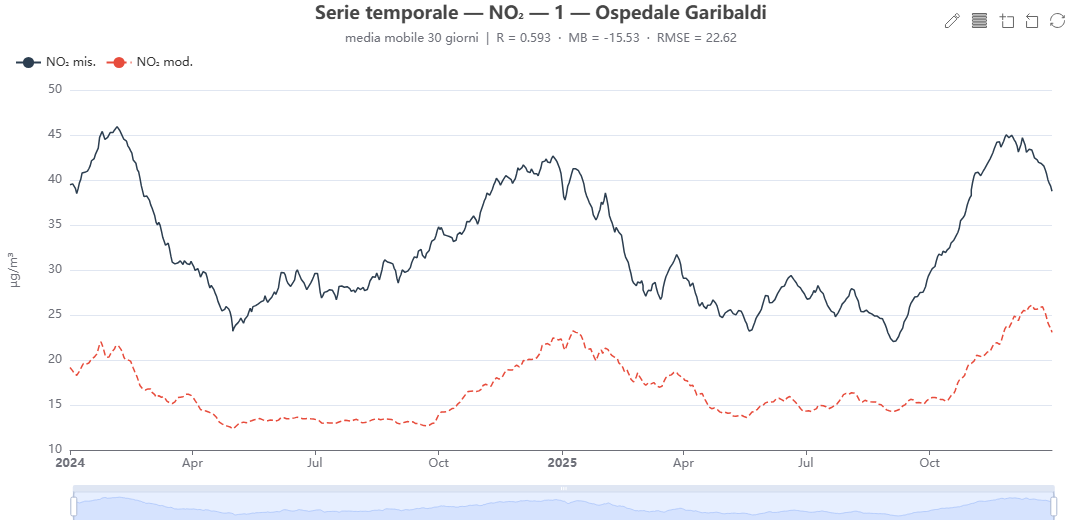
Serie temporale modello vs osservato 🕒 dati dal server
Cosa mostra. Le due serie (misurato e modello) sovrapposte nel tempo, con aggregazione selezionabile (giornaliera, media mobile a 7 o 30 giorni, mensile) e una banda dei residui (modello − osservato) opzionale.
Come si costruisce. Dalle medie giornaliere obs/mod (calendar_data); aggregazione e residui sono calcolati lato client sui giorni in cache. R, MB e RMSE globali sono riportati nel sottotitolo.
Perché lo usiamo. È la diagnostica più immediata e completava una lacuna evidente: rende visibili episodi, derive stagionali e periodi anomali che le metriche aggregate nascondono.
Ciclo diurno
Cosa mostra. Il ciclo medio giornaliero (mediana oraria P50) di misurato (linea continua) e modello (tratteggiata), per ogni inquinante presente.
Come si costruisce. Dai percentili (stratificazione «hour»).
Perché lo usiamo. Verifica la riproduzione del ciclo giornaliero (traffico, fotochimica) e mette in luce eventuali sfasamenti orari.

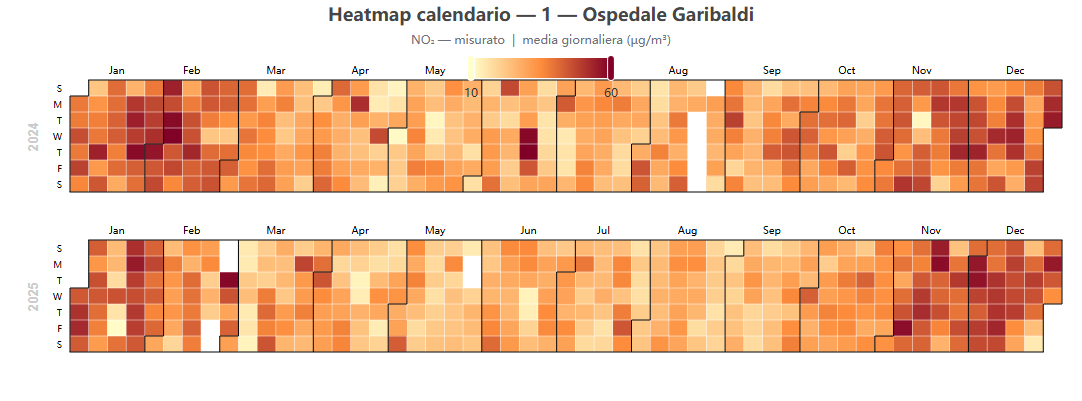
Heatmap calendario 🕒 dati dal server
Cosa mostra. Un calendario annuale in cui ogni giorno è colorato per la media giornaliera (misurato, modello oppure bias modello − misurato).
Come si costruisce. Da calendar_data (medie giornaliere obs/mod).
Perché lo usiamo. Offre una vista d'insieme di stagionalità, episodi acuti e lacune nei dati, difficile da cogliere in una serie continua.
Clock plot bias giornaliero
Cosa mostra. Un indicatore scelto disposto su un quadrante a 24 ore (le ore in cerchio), per leggere la variazione della metrica lungo la giornata.
Come si costruisce. Dai dati di validazione (stratificazione «hour»), con scala divergente per le metriche di bias.
Perché lo usiamo. Evidenzia in modo compatto e intuitivo le ore del giorno in cui la metrica (es. il bias) si concentra.
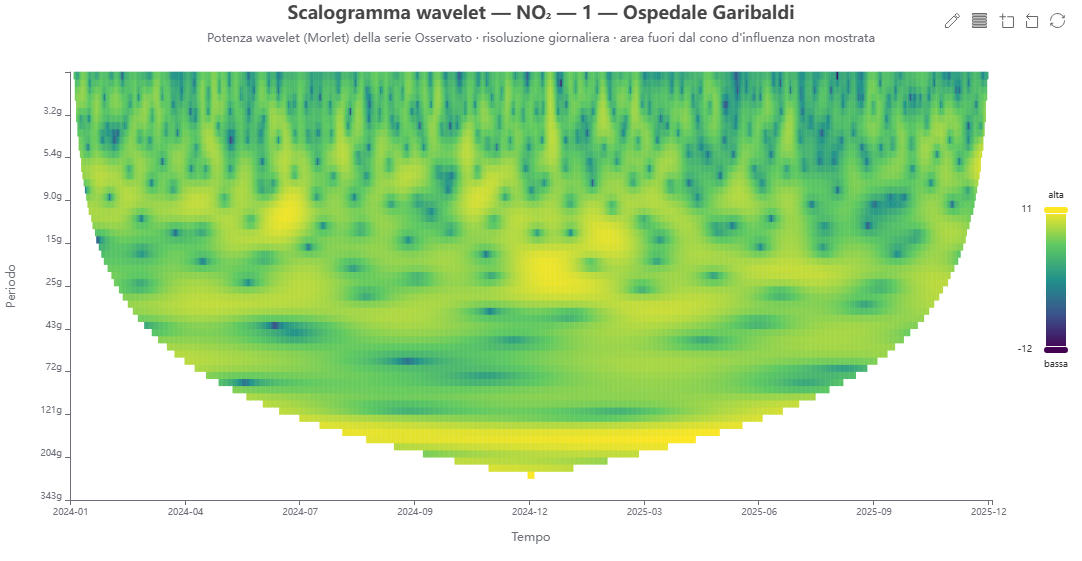
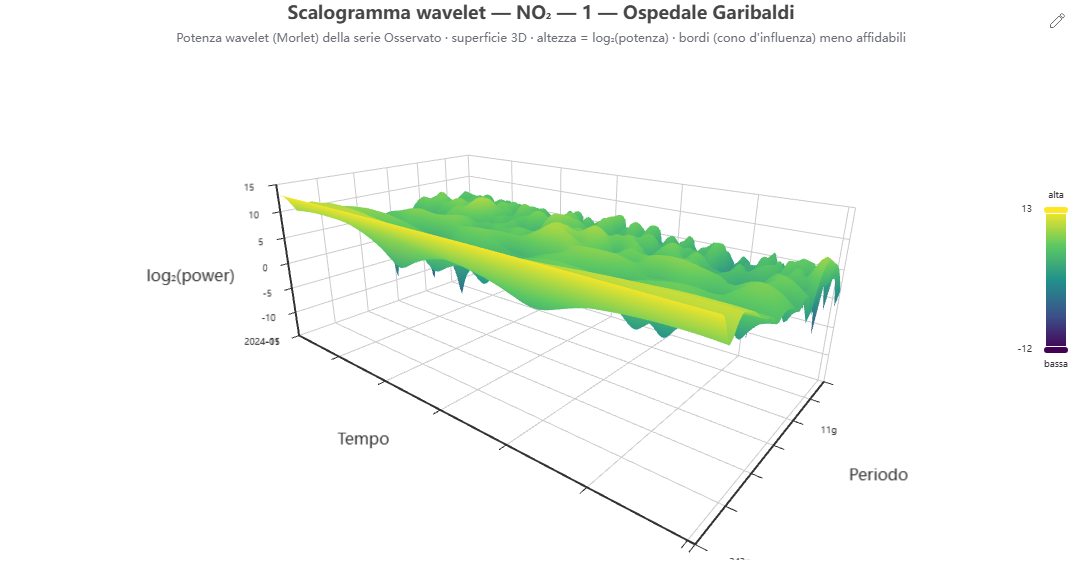
Scalogramma wavelet 🕒 dati dal server
Cosa mostra. La potenza wavelet (Morlet) della serie scelta (osservato o modello) nel piano tempo×periodo: dove e quando una periodicità (diurna, settimanale, mensile…) è più intensa. L'area fuori dal cono d'influenza non è mostrata.
Come si costruisce. La serie giornaliera o oraria (selettore di risoluzione) è scaricata via calendar_data/series_hourly; la trasformata wavelet continua di Morlet è calcolata lato client (FFT), con potenza |W|² in scala logaritmica (log₂). Le colonne sono sottocampionate per la resa.
Perché lo usiamo. A differenza di un ciclo medio, localizza nel tempo l'intensità delle periodicità e ne mostra la non‑stazionarietà (es. ciclo diurno più marcato d'estate, episodi).
Vista 2D/3D. Un selettore permette di passare dalla mappa di calore 2D alla superficie 3D interattiva (altezza = log₂ della potenza), che fa risaltare le creste delle periodicità dominanti e la loro evoluzione nel tempo. Nella vista 3D la superficie include anche il cono d'influenza (bordi meno affidabili) e il tempo è sottocampionato più finemente per restare fluida.
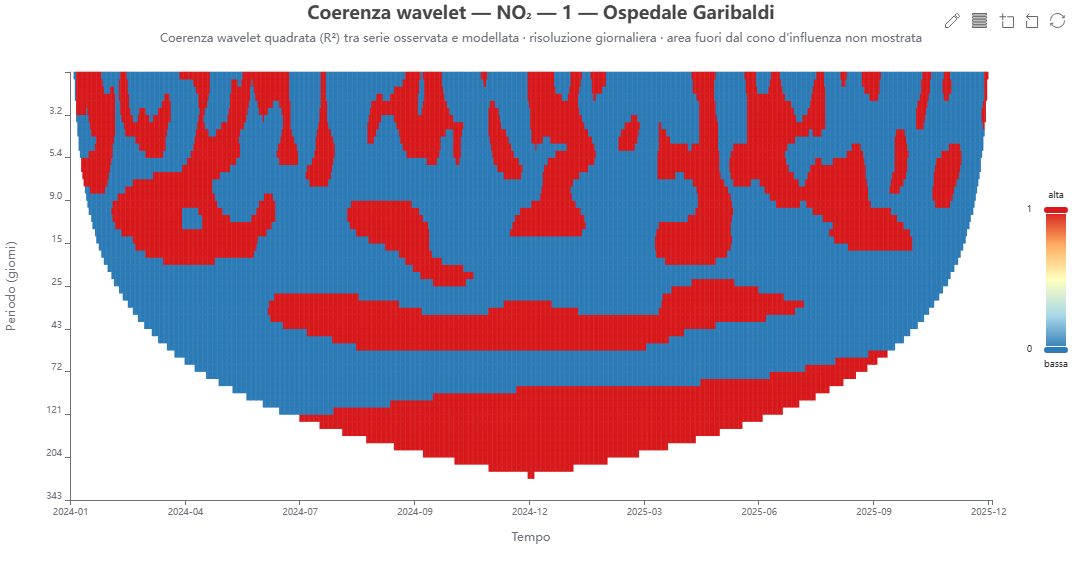
Coerenza wavelet osservato↔modello 🕒 dati dal server
Cosa mostra. La coerenza wavelet quadrata R² (tempo, periodo), compresa fra 0 e 1, tra osservato e modello: a quali scale temporali e in quali periodi il modello riproduce la struttura ciclica delle osservazioni.
Come si costruisce. Trasformate wavelet di osservato e modello sulla stessa griglia giornaliera, cross‑spettro smussato nel tempo e nella scala (Torrence & Webster 1999); l'area fuori dal cono d'influenza non è mostrata.
Perché lo usiamo. Diagnostico di validazione oltre la correlazione globale: indica se il modello cattura il ciclo diurno/settimanale e dove perde coerenza.
Decomposizione STL (trend / stagionalità / residuo)
Cosa mostra. La decomposizione STL della serie giornaliera in quattro pannelli allineati (serie, trend, stagionalità, residuo), con osservato e modello sovrapposti e commutabili dalla legenda; lo zoom temporale è sincronizzato fra i pannelli.
Come si costruisce. Legge la STL precalcolata (statsmodels, periodo settimanale) tramite l'endpoint stl_data.
Perché lo usiamo. Separa l'andamento di fondo (trend), il ciclo (stagionalità) e le anomalie (residuo, es. episodi Etna), e confronta direttamente le tre componenti di osservato e modello.

Cicli ora × stagione
Heatmap e clock plot che incrociano l'ora del giorno con il mese o la stagione, per leggere i pattern periodici combinati.
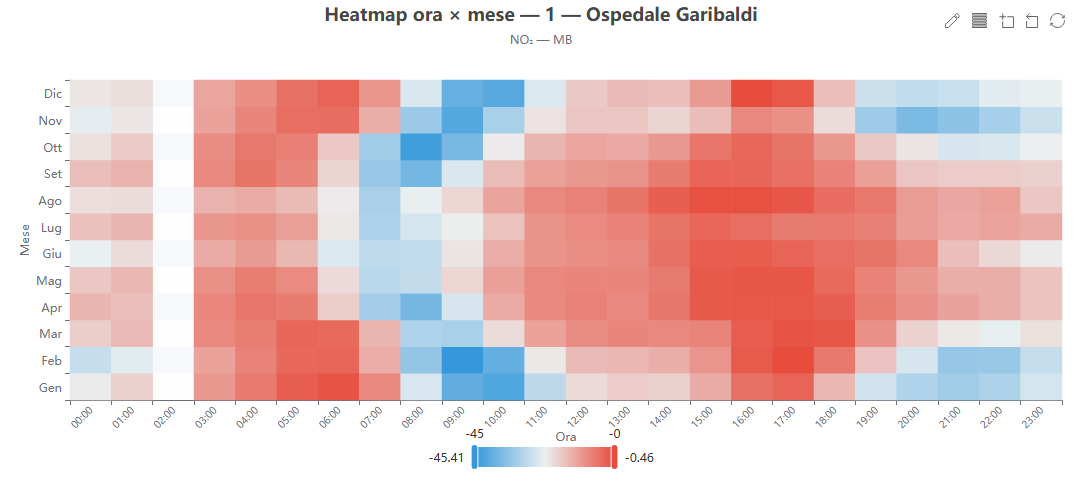
Heatmap ora × mese (piano)
Cosa mostra. Una griglia 24 ore × 12 mesi colorata per la metrica scelta (oppure per la concentrazione grezza mediana).
Come si costruisce. Dai dati di validazione o dai percentili (stratificazione «hour_month»).
Perché lo usiamo. Rivela pattern combinati ora–stagione, come i picchi pomeridiani estivi di ozono.
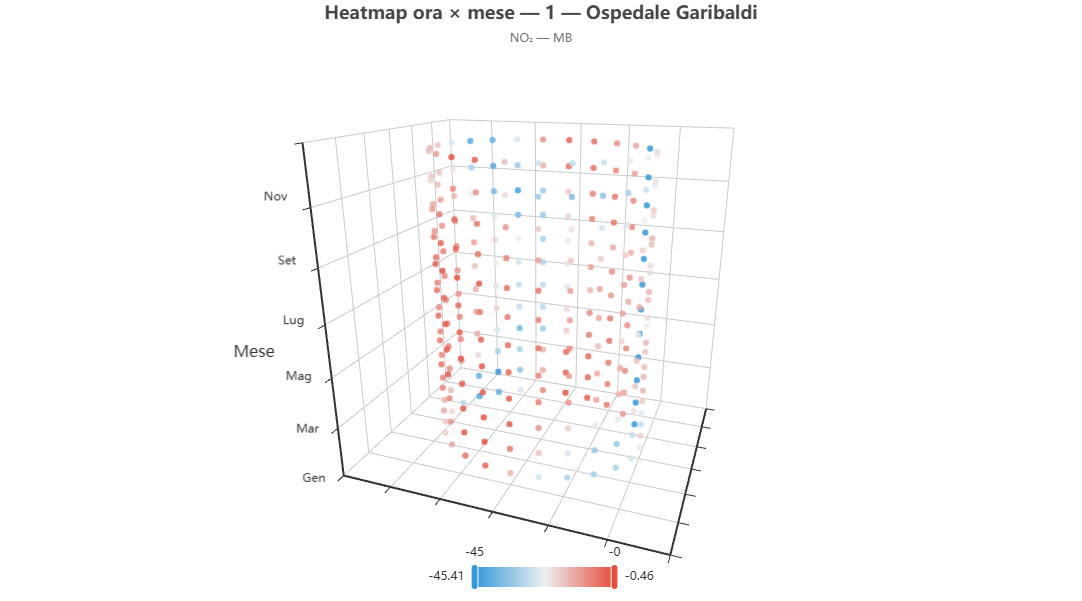
Heatmap ora × mese (cilindro)
Cosa mostra. La stessa informazione avvolta su un cilindro 3D: l'angolo è l'ora, l'altezza il mese.
Come si costruisce. Gli stessi dati della versione piana, proiettati su una superficie cilindrica (ECharts GL).
Perché lo usiamo. La forma cilindrica elimina la discontinuità artificiale fra l'ora 23 e l'ora 0, restituendo la vera periodicità giornaliera.
Heatmap stagione × ora (piano)
Cosa mostra. Una griglia stagione × ora colorata per la metrica scelta o la concentrazione grezza.
Come si costruisce. Dai dati di validazione / dai percentili (stratificazione «season_hour»).
Perché lo usiamo. Confronta direttamente il ciclo diurno fra le quattro stagioni.

Heatmap stagione × ora (cilindro)
Cosa mostra. La versione cilindrica 3D della heatmap stagione × ora.
Come si costruisce. Stessi dati «season_hour» su superficie cilindrica (ECharts GL).
Perché lo usiamo. Lettura continua del ciclo orario, senza salto 23→0, per ciascuna stagione.

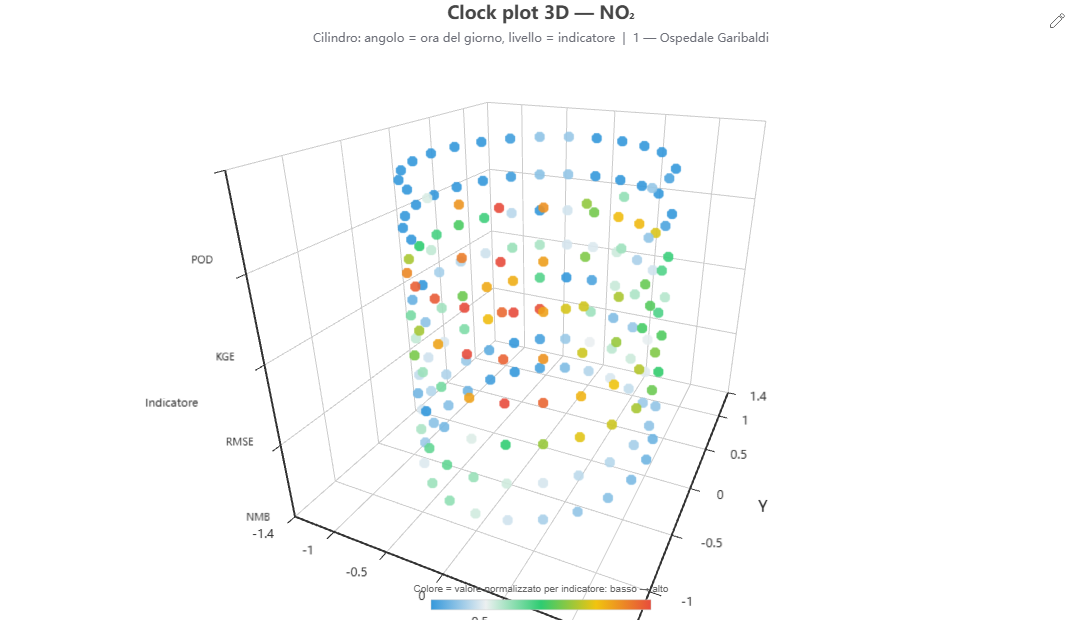
Clock plot 3D (cilindro)
Cosa mostra. Un cilindro in cui l'angolo è l'ora del giorno e i livelli sull'asse Z sono i diversi indicatori, con valori normalizzati a colore.
Come si costruisce. Dai dati di validazione (stratificazione «hour»); ogni indicatore è normalizzato sul proprio intervallo. Possibile la media su tutte le centraline.
Perché lo usiamo. Confronta più indicatori lungo il ciclo orario in un'unica figura.
Distribuzioni
Grafici che confrontano la forma delle distribuzioni di misure e modello, oltre alle sole medie.
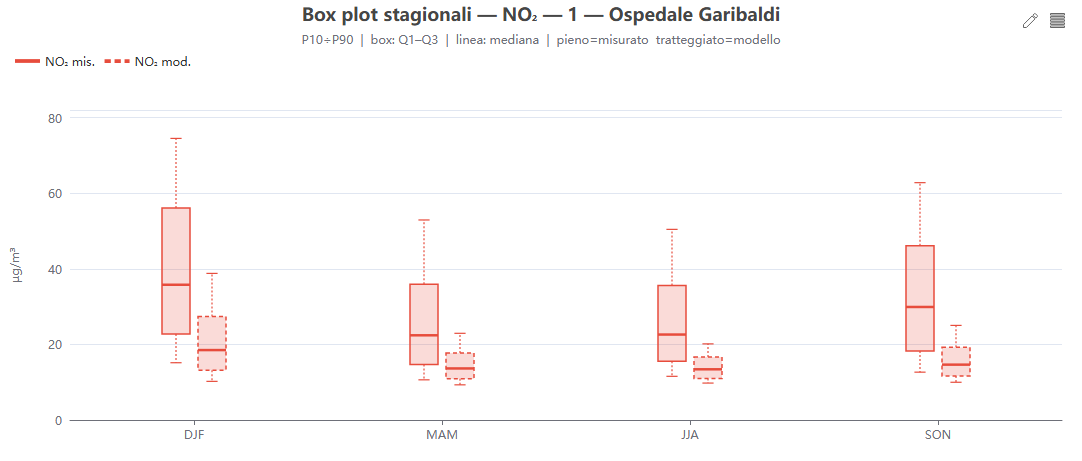
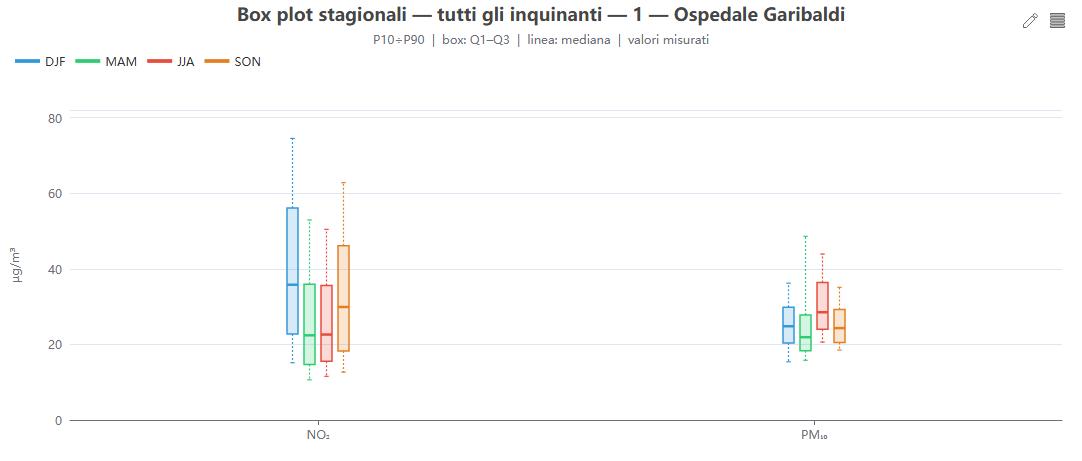
Box plot stagionali per inquinante
Cosa mostra. Box plot stagionali (P10 – Q1 – mediana – Q3 – P90) per un singolo inquinante, con misurato e modello affiancati; un selettore cambia inquinante.
Come si costruisce. Dai percentili (stratificazione «season»).
Perché lo usiamo. Confronta la dispersione stagionale, non solo i valori centrali, mostrando se il modello comprime o allarga la distribuzione.
Box plot stagionali per tutti gli inquinanti
Cosa mostra. I box plot stagionali di tutti gli inquinanti insieme, con uno switch misurato/modello.
Come si costruisce. Dai percentili (stratificazione «season»).
Perché lo usiamo. Panoramica comparativa della variabilità fra le diverse specie.
Confronto percentili di picco (P90/P95/P99)
Cosa mostra. Barre raggruppate dei percentili alti (P90, P95, P99) osservati e modellati per ciascun inquinante.
Come si costruisce. Dai percentili (stratificazione «global»).
Perché lo usiamo. I percentili alti governano gli sforamenti normativi: qui si verifica se il modello riproduce i livelli di picco.

Banda percentili mensile (P50 + P10–P90)
Cosa mostra. Per ciascun mese dell'anno (gen–dic) la mediana (P50) di osservato e modello, con la banda P10–P90 dell'osservato: il livello tipico e la dispersione mensile a confronto.
Come si costruisce. Dai percentili mensili (stratificazione «month», sorgenti «measured» e «model»).
Perché lo usiamo. Mostra la climatologia mensile e verifica se il modello coglie il livello mediano e l'ampiezza della variabilità lungo l'anno.

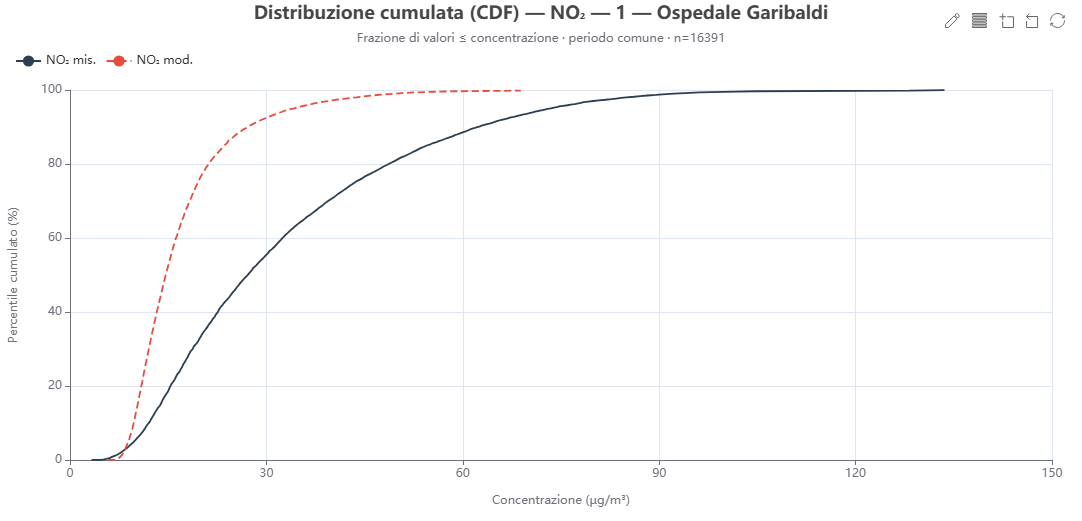
Curve di distribuzione cumulata (CDF) 🕒 dati dal server
Cosa mostra. Le curve cumulate empiriche (ECDF) di osservato e modello sul periodo comune: per ogni concentrazione, la frazione di valori inferiori o uguali.
Come si costruisce. Dalle coppie di scatter_data; i valori sono ordinati e sottocampionati per leggerezza.
Perché lo usiamo. Confronto distributivo completo (non solo sette percentili), complementare a Q-Q e box plot.
Sintesi multi-metrica
Grafici che condensano più indici in un'unica vista d'insieme.
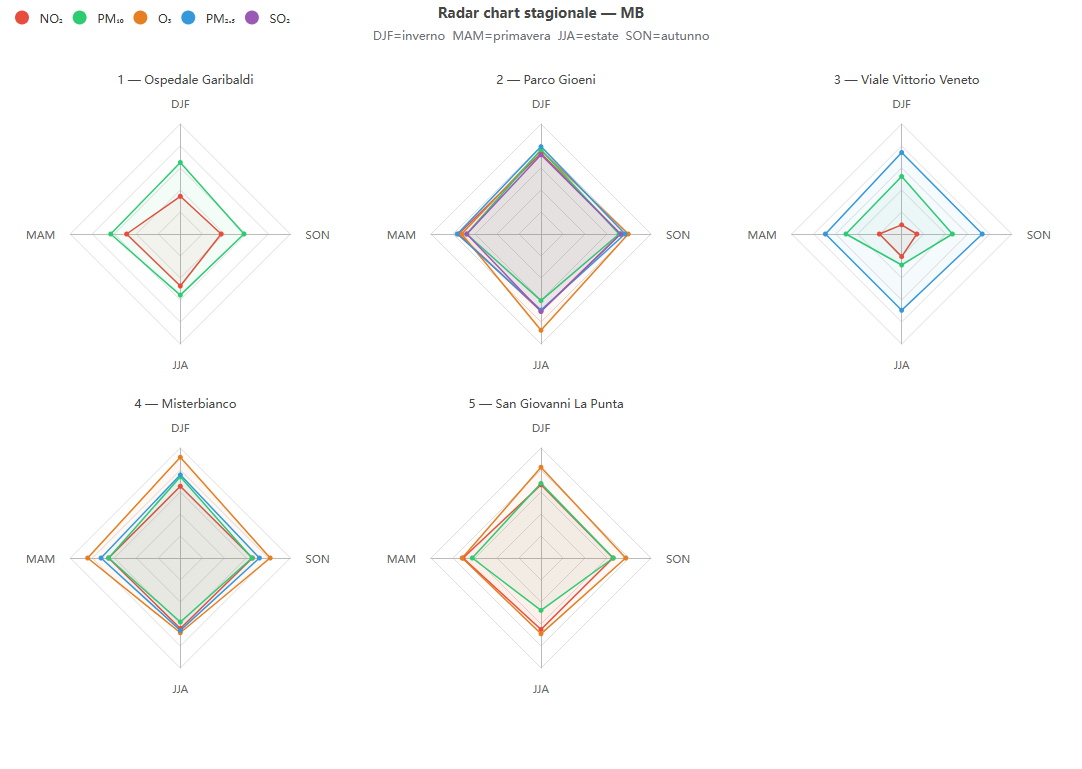
Radar chart stagionale
Cosa mostra. Un radar per centralina con i quattro vertici = stagioni, che traccia il valore di una metrica scelta; gli inquinanti sono serie sovrapposte.
Come si costruisce. Dai dati di validazione (stratificazione «season»).
Perché lo usiamo. Confronta a colpo d'occhio la metrica fra stagioni, inquinanti e centraline.
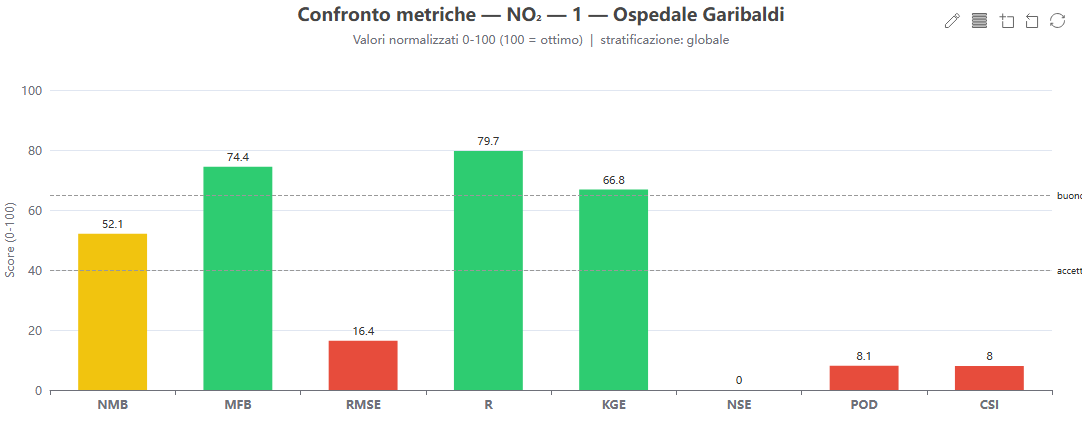
Bar chart comparativo multi-metrica
Cosa mostra. Le barre di tutte le metriche, normalizzate 0–100 (100 = ottimo) per un inquinante/centralina, colorate per fascia di qualità.
Come si costruisce. Dai valori grezzi di validazione normalizzati con le stesse regole dello score; rispetta la stratificazione selezionata (globale/stagione/ora).
Perché lo usiamo. È un cruscotto sintetico dei punti di forza e di debolezza del modello su un'unica scala confrontabile.
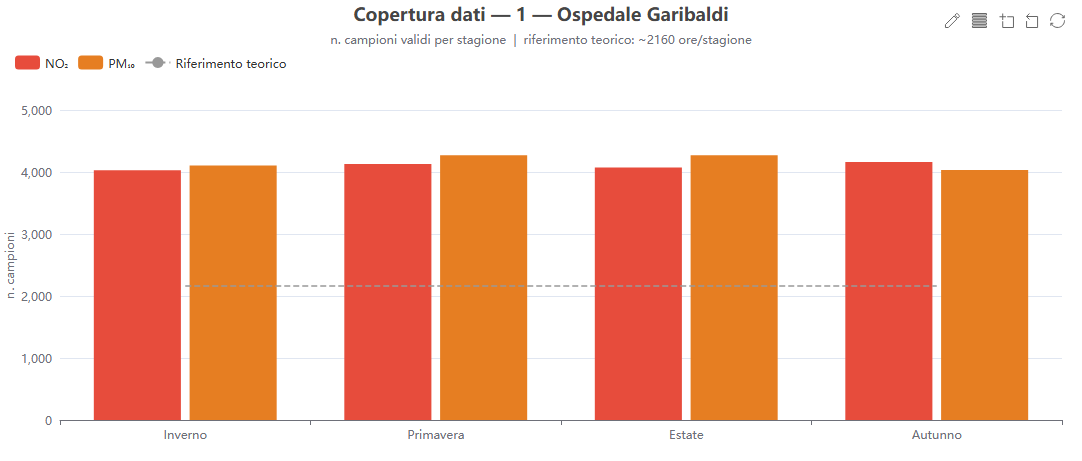
Copertura dati (n campioni) per stagione
Cosa mostra. Le barre del numero di campioni validi per stagione e inquinante, con una linea di riferimento teorico (~2160 ore/stagione).
Come si costruisce. Dal campo n_samples di i dati di validazione (stratificazione «season»).
Perché lo usiamo. La copertura dei dati condiziona l'affidabilità di tutte le metriche: poche ore valide rendono fragili gli indici.
Spaziale e multivariato
Grafici che aggiungono la dimensione spaziale o mettono in relazione più variabili contemporaneamente.
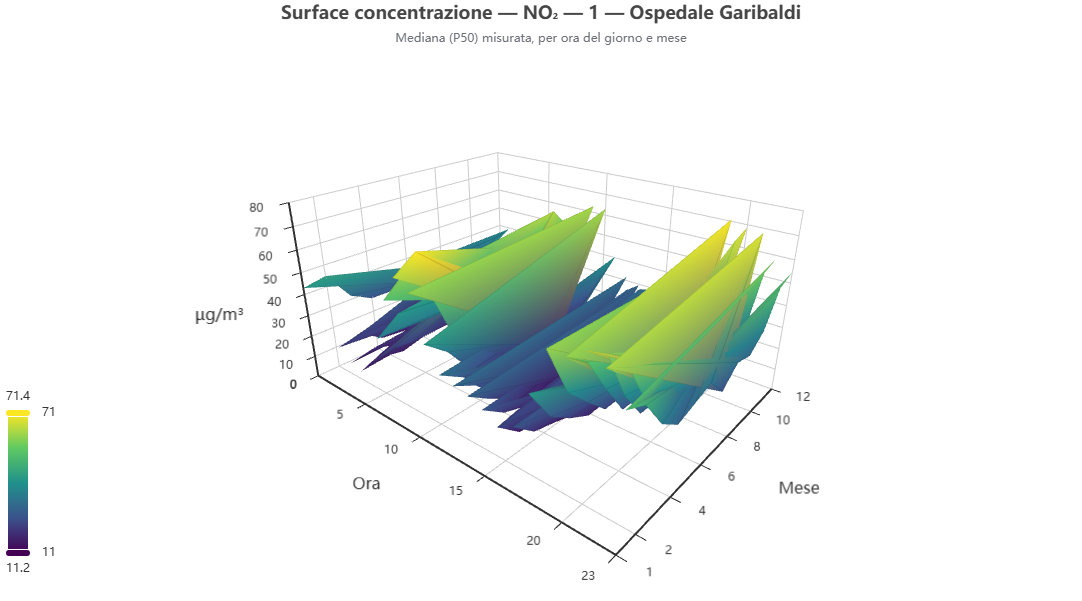
Surface plot concentrazione
Cosa mostra. Una superficie 3D della concentrazione mediana misurata in funzione di ora del giorno e mese.
Come si costruisce. Dai percentili (stratificazione «hour_month», P50 misurato), resa con ECharts GL.
Perché lo usiamo. Vista tridimensionale d'insieme del comportamento ciclico, utile per cogliere creste e avvallamenti stagionali.
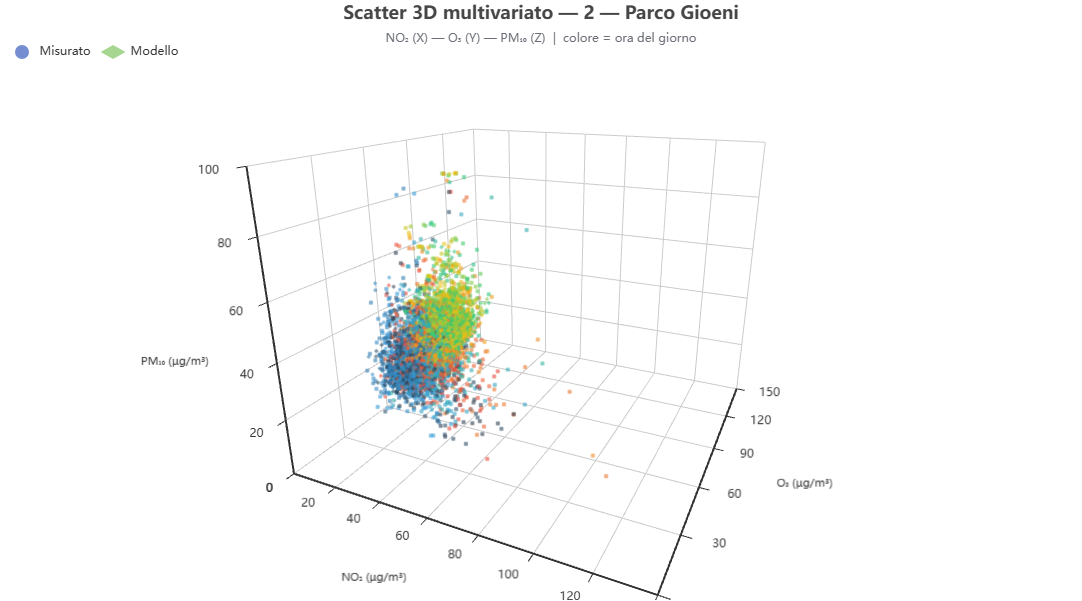
Scatter 3D multivariato 🕒 dati dal server
Cosa mostra. Una nuvola 3D di tre inquinanti contemporaneamente (un asse ciascuno), per esplorare relazioni multivariate — per esempio la titolazione di Leighton fra NO₂, O₃ e PM₂.₅.
Come si costruisce. Da scatter3d_data (valori allineati nel tempo per le tre specie).
Perché lo usiamo. Alcune relazioni chimiche emergono solo guardando tre variabili insieme, non a coppie.
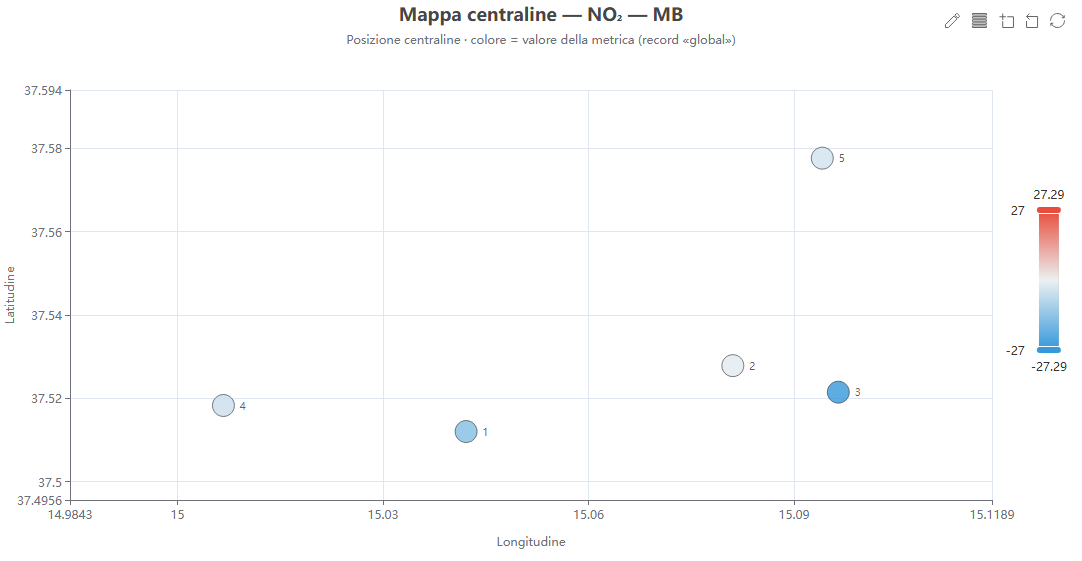
Mappa per centralina (metrica)
Cosa mostra. Le centraline posizionate per longitudine/latitudine e colorate secondo la metrica scelta (scala divergente per i bias).
Come si costruisce. Dai dati di validazione (record «global») e dalle coordinate delle stazioni; senza tile di base, evidenzia il pattern spaziale relativo.
Perché lo usiamo. Rivela strutture spaziali dell'errore (es. sottostima sistematica nelle aree urbane) non visibili nelle tabelle.
Animazione griglia concentrazione (3D) 🕒 dati dal server
Cosa mostra. Un'animazione 3D del campo di concentrazione del modello su una griglia intorno alla centralina, con un player temporale.
Come si costruisce. Da grid_animation_data (celle e frame caricati a finestre), resa con ECharts GL.
Perché lo usiamo. Mostra l'evoluzione spazio‑temporale di un episodio o di un pennacchio, impossibile da rendere con una serie puntuale.

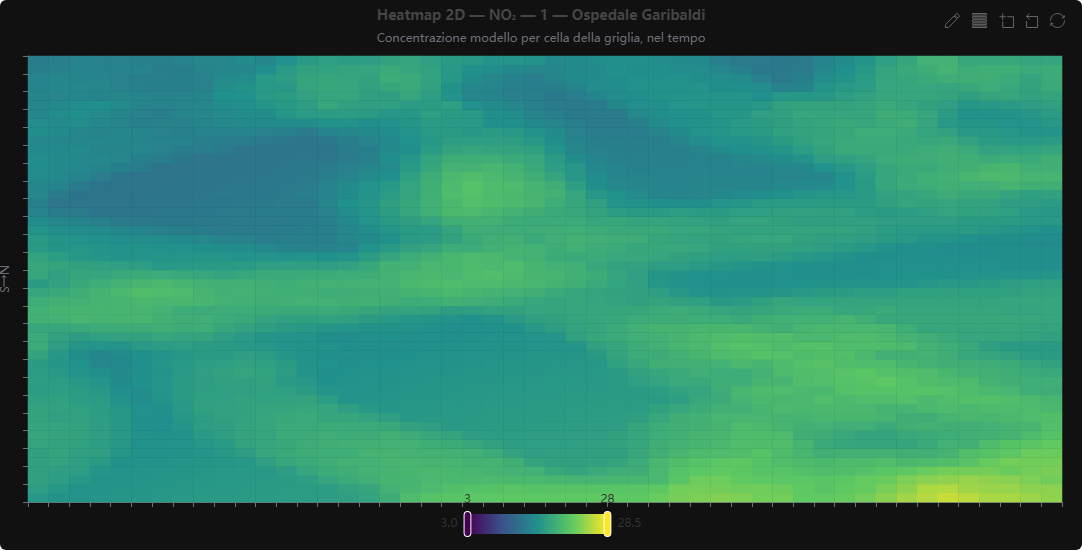
Time-lapse heatmap 2D su mappa 🕒 dati dal server
Cosa mostra. Lo stesso campo del modello come heatmap 2D a griglia, animata nel tempo con player.
Come si costruisce. Da grid_animation_data; le celle sono indicizzate per longitudine e latitudine.
Perché lo usiamo. Lettura planare e immediata dell'evoluzione temporale, complementare alla resa 3D.